
This is the second post of a four-part series on simple statistics for clinical trials. Without too much technical detail, this series of posts is intended to offer some background in how statistical planning can influence study effectiveness and value.
Planning a successful human in-use clinical study begins with some central questions. What question do we want to answer? What statistical methods will help us answer that question? What data do we need to collect? How will we collect it? From whom and from how many? What other factors might influence our results? The answers to all these questions are influenced by an understanding of statistics. You need the support of a qualified clinical statistician, part of an established, trustworthy, professional clinical testing team, to develop a clinical trial that offers the most accurate information.
Hypothesis testing
One central concept in clinical statistics is hypothesis testing. In a seemingly counterintuitive twist, hypothesis testing begins with a “null hypothesis” (expressed mathematically as H0) or the premise that the product does not perform—that there is no difference between user experience with and without the product. Then, a study is designed to test this hypothesis.
Continuing in the vein of counterintuition, the four possible outcomes in hypothesis testing are described like this:
- True Positive: The product actually makes a difference in the user experience (H0 is false), and the test agrees (rejects H0).
- True Negative: The product actually makes no difference in the user experience (H0 is true) and the test agrees (fails to reject H0).
- False Positive: The product makes no difference (H0 is True), but the test shows that it does (falsely rejects H0). This is called a Type I Error.
- False Negative: The product makes a difference (H0 is False), but the test shows no difference (fails to reject H0). This is known as a Type II Error.
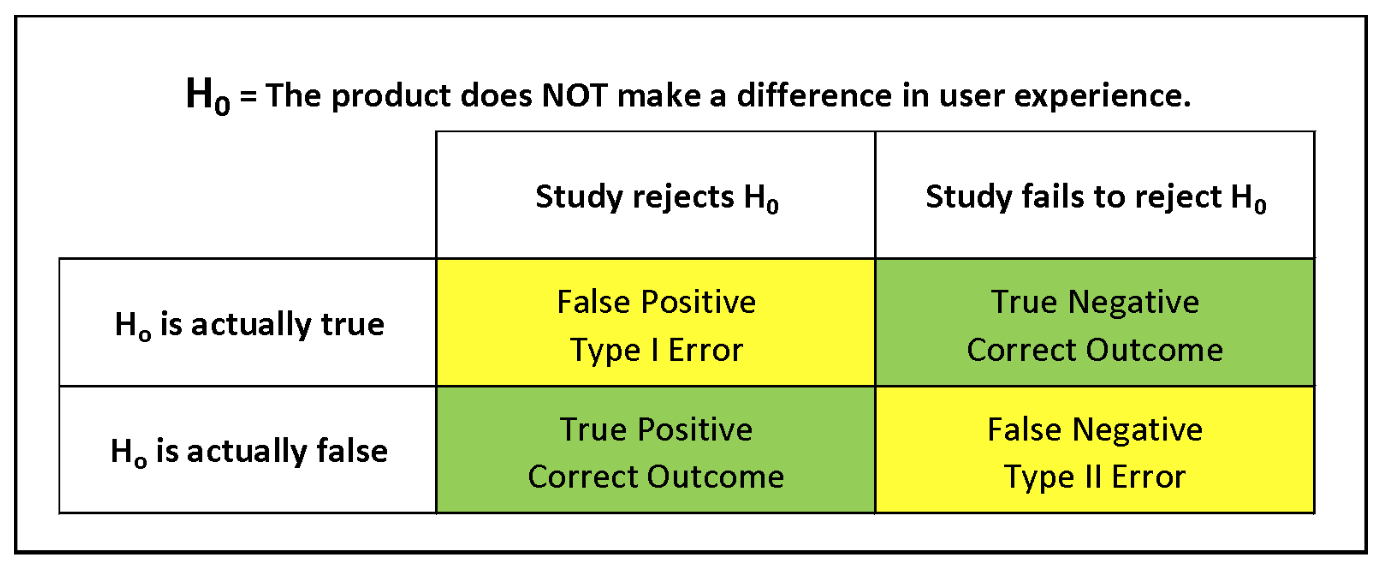
To summarize: Type I errors in clinical testing indicate that there is a product effect that does not occur, while Type II errors fail to indicate a product effect that actually does occur. Either type of error can be more problematic, depending on the product being tested and the specific characterization of the null hypothesis.
Study populations:
Significance, power, variation, and sample size
The significance level indicates the probability of a Type I error occurring. Statistical power indicates the test’s ability to avoid a Type II error. Variability in data can be expressed as standard deviation but also as range and IQR. Which is more meaningful can depend on data structure. Sample size influences all these aspects of clinical evaluation and is a critical foundation of quality study design.
A sample size that is too small can result in insufficient data for reliable analysis; a sample size that is larger than necessary can result in wasted resources. A number of statistical tools help determine the ideal sample size for a given study. Part III of this series will offer more information about clinical study population planning.
Be sure to figure in the statistics
A qualified professional clinical statistician can guide the study planning team in deciding how many subjects to recruit for the study as well as help recommend target demographics for the subject population. Making critical decisions about the study population is a key initial step in successful clinical trial planning, so be sure to work with an established, trustworthy, professional clinical testing team that gets a qualified professional clinical statistician involved in the planning process early.

